Removing Duplicate Rows with ROW_NUMBER()
Sometimes you will come across a dataset that contains two or more rows of the same data, in a data warehouse for example this is common especially if you have a snapshot table that is capturing rows day by day for other purposes.
So what happens if we wanted to query these tables but only return one instance of each row, maybe the most recent row recorded? Using Row_Number() we can do that and I am going to show you how.
Some sample data
To demonstrate I have provided some sample data, 5 rows of each product, all products have the same ProductSubTypeID but the DateAdded starts at the current day then -1 for each subsequent row.
CREATE TABLE #DuplicateRows
(
ID INT IDENTITY(1,1),
ProductID INT,
ProductSubTypeID INT,
DateAdded DATETIME
)
INSERT INTO #DuplicateRows (ProductID,ProductSubTypeID,DateAdded)
VALUES
(1,2,GETDATE()),
(1,2,DATEADD(dd,-1,GETDATE())),
(1,2,DATEADD(dd,-2,GETDATE())),
(1,2,DATEADD(dd,-3,GETDATE())),
(1,2,DATEADD(dd,-4,GETDATE())),
(1,2,DATEADD(dd,-5,GETDATE())),
--
(2,2,GETDATE()),
(2,2,DATEADD(dd,-1,GETDATE())),
(2,2,DATEADD(dd,-2,GETDATE())),
(2,2,DATEADD(dd,-3,GETDATE())),
(2,2,DATEADD(dd,-4,GETDATE())),
(2,2,DATEADD(dd,-5,GETDATE())),
--
(3,2,GETDATE()),
(3,2,DATEADD(dd,-1,GETDATE())),
(3,2,DATEADD(dd,-2,GETDATE())),
(3,2,DATEADD(dd,-3,GETDATE())),
(3,2,DATEADD(dd,-4,GETDATE())),
(3,2,DATEADD(dd,-5,GETDATE())),
--
(4,2,GETDATE()),
(4,2,DATEADD(dd,-1,GETDATE())),
(4,2,DATEADD(dd,-2,GETDATE())),
(4,2,DATEADD(dd,-3,GETDATE())),
(4,2,DATEADD(dd,-4,GETDATE())),
(4,2,DATEADD(dd,-5,GETDATE())),
--
(5,2,GETDATE()),
(5,2,DATEADD(dd,-1,GETDATE())),
(5,2,DATEADD(dd,-2,GETDATE())),
(5,2,DATEADD(dd,-3,GETDATE())),
(5,2,DATEADD(dd,-4,GETDATE())),
(5,2,DATEADD(dd,-5,GETDATE()))
As you can see, we have many products all with the same ProductSubTypeID which won’t matter but the data for each row grouped by ProductID is the same, if we were to run a query to get us all products with ProductID = 1 for example;
SELECT * FROM #DuplicateRows WHERE ProductID = 1
We are going to get 5 rows returned, which in this example, isn’t what we want.
The Query
So, how can we get just that one row? Lets write the query and have a look.
;WITH RemoveDuplicates AS
(
SELECT
ProductId,
ProductSubTypeID,
DateAdded,
ROW_NUMBER() OVER(PARTITION BY ProductID ORDER BY DateAdded DESC) as RowNum
FROM #DuplicateRows
)
SELECT
ProductId,
ProductSubTypeID,
DateAdded,
RowNum
FROM
RemoveDuplicates WHERE RowNum = 1
We have created a CTE (Common Table Expression) to give every row in our sample data a RowNumber which is better highlighted in the screenshot below
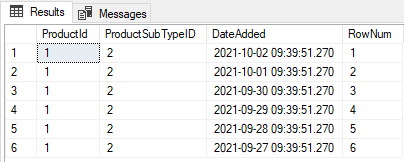
The Row_Number function is partitioning the table by the ProductId then ordering each row based on the DateAdded in Descending order to assign each row for each ProductID a number, so occurance 1 of Product 1 with the newest date gets RowNumber 1 and so on until there are no more rows for ProductId 1 remaining then the RowNumber starts again for the next ProductID and so on and so on until all rows that satisy the partition are numbered.
What we can then do is select all rows from the CTE which we called RemoveDuplicates where RowNum = 1 and only rows that were given Row Number 1 will be returned as you can see below
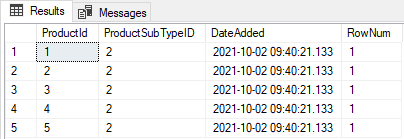
There are other ways that this result could be achived but I wanted to demonstrate how Row_Number() could be utilised.